Game AI Behavior Framework
Oct 27, 2025
by Nik Kim
Introduction
When people gather, drama happens. I believe this is why seemingly simple open-world multiplayer games like Minecraft are so popular. With only basic mechanics, a world, and minimal story, the game creates endless fun, largely because of the players around you.
At first glance, building AI agents to roam such infinite worlds seems like a far greater challenge than designing AI for a tightly scripted game. Open worlds are unpredictable, full of emergent behaviors, and lack of control, so AI must appear responsive even in situations designers never anticipated. In contrast, scripted games allow tighter control, predictable encounters, and AI tuned to specific event beats.
But paradoxically, open-world AI might actually be an easier path to compelling play. In these spaces, drama doesn't have to come from carefully authored mechanics or scripted encounters. It comes from social interaction. Rather than trying to define what makes AI interaction fun, we can focus on enabling interaction itself and let the outcomes follow.
Then the question becomes: how can open-world AI agents perform intentional and purposeful behaviors that align with game mechanics, as if humans were playing the game? Luckily, game developers have tackled this problem in many ways, giving rise to AI frameworks such as Behavior Trees, Finite State Machines, Utility AI, and Goal-Oriented Action Planning (GOAP).
However, one area that hasn't been fully explored is how these frameworks can interface with LLMs and other modern AI technologies. LLMs have the potential to deeply shape an AI's character, thanks to their generative capabilities and ability to digest large amounts of textual information. Yet they have a limitation: LLMs excel at producing rich textual data, but this output must be translated into embodied behaviors in dynamic environments.
This highlights the need for a behavioral framework serving as a crucial interface between abstract AI models and the concrete actions of in-game characters within a game engine.
That being said, this framework may be an interim solution on the path toward a true foundational behavior model, (independent, self-learning, ready-to-be-deployed model across various platforms) but for now, it is a necessary and practical stepping stone.
Approach
This post introduces a hybrid AI behavior framework that serves as this crucial interface. It combines the reactive, moment-to-moment decision-making of Utility AI with the structured, long-term planning of Goal-Oriented Action Planning (GOAP). More importantly, it is designed with specific 'hooks' where a large language model or other generative AI can inject influence. These hooks include modulating an AI's personality, setting long-term goals, and directing high-level contextual awareness, allowing an LLM to act as a 'director' of the character's intent while the framework handles the complex execution of that intent within the game world.
Framework Criteria
For this framework to be successful, it must meet several key criteria:
- Scalability: Can it handle a large and growing set of actions, characters, and environmental states?
- Debuggability: Is the output action can be easily regenerated and troubleshooted?
- Modularity: Can components, like planning systems, can be easily swapped to different systems based on needs?
- Explainability: Does the output action make sense and can be evaluated?
Framework Evolution
Utility-Based Instantaneous Actions
The first experiment applied Utility AI using the Wise Feline plugin in Unreal Engine to create instantaneous actions. The setup was simple: an AI agent roamed randomly and fired projectiles when it detected a target (another AI or the player). This followed a tutorial from the NoOp Army Games Wise Feline documentation.
Despite the simplicity, the results were convincing. The AI's movement resembled FPS-style enemies, demonstrating Utility AI's strength in fast decision making and action execution with minimal configuration.


Utility-Based Life Simulation
The next step tested Utility AI in a longer-term context: life simulation. The AI had a small set of actions: Cry, Roam and Wait, Go to Bed, Sleep, and Go to Kitchen. We introduced _age_ as a consideration, alongside needs such as hunger and stamina. As a result, a baby AI cried when tired or hungry, while older AIs could go to bed or the kitchen on their own.
This experiment demonstrated the potential of Utility AI to create more nuanced and adaptive behavior over time, without the need for complex planning systems.
Multi-Behavior Approach
In Wise Feline, a behavior is simply a set of actions. For example, a behavior might directly consist of actions such as Eat, Sleep, and Get Clean. This could be labeled as a “Needs” behavior.
In our approach, however, we introduced an additional layer by **grouping related actions into higher-level behavior categories**. Instead of handling every action in one flat pool, we organized them into contextual sets such as “Needs,” “Social,” “Hobby,” or “Work.” This strategy helped address the scalability and debugging challenges that arise when a single behavior grows too large.
The idea of dividing behaviors by context also mirrors human decision-making. When we play a video game, for instance, we do not consider actions related to work or exercise. Our available actions are always constrained by the context we are in.
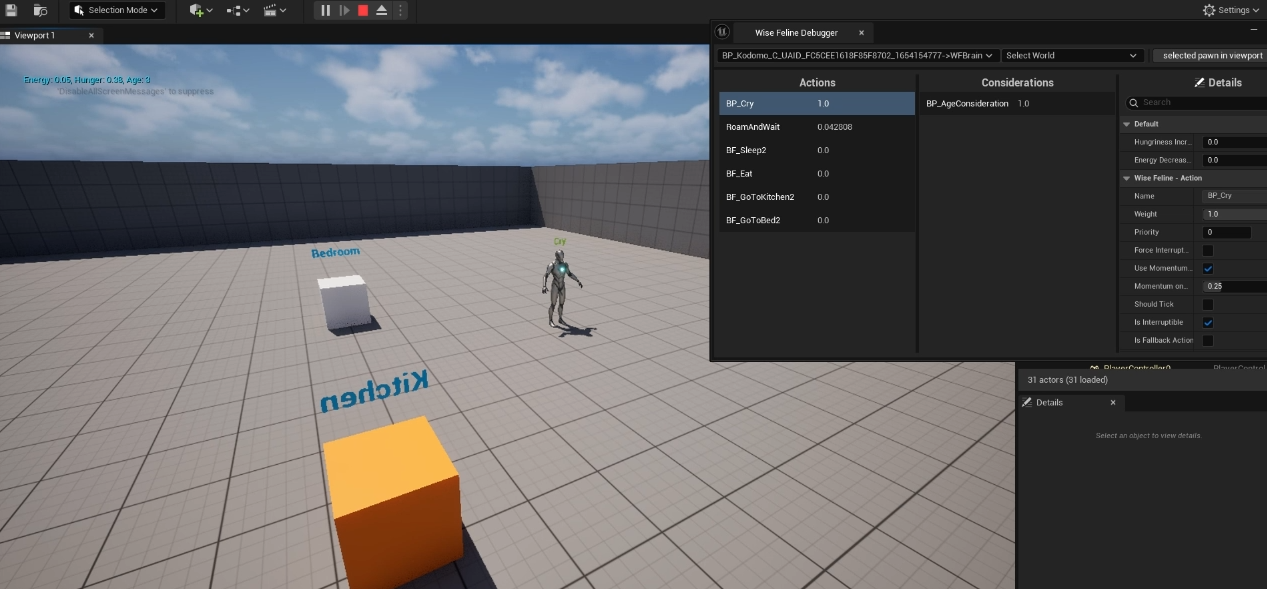
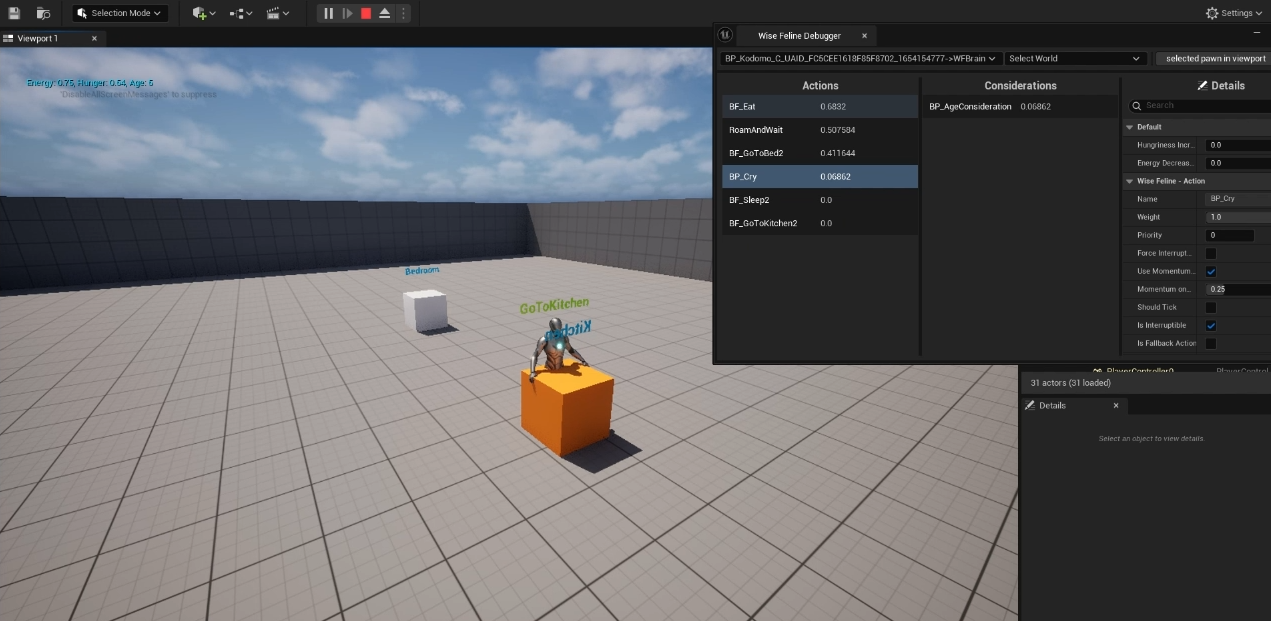
We tested this method using age as the contextual factor. Age is a natural example of how context confines behavior. Each age group—Baby, Child, Teenager, and Adolescent—was associated with a distinct set of actions and considerations. Among these, the Adolescent stage had the largest and most complex configuration. Switching between age-based behaviors was implemented simply by enabling the corresponding behavior component.
As shown in the screenshots below, tweaking the consideration values within a given stage led to different selected actions, demonstrating how contextual grouping improved both clarity and control in AI behavior design.

Planning and Long-term Actions
Splitting behaviors solved scalability and debugging issues, but Utility AI still lacked the ability to plan and execute long-term actions. To address this, we integrated Utility AI with Goal-Oriented Action Planning (GOAP).
In this hybrid system:
- Utility AI serves as a goal setter, selecting goals based on internal values.
- GOAP serves as the planner, generating a sequence of atomic actions to achieve the goal.
This allows the AI to dequeue and execute complex plans step by step.
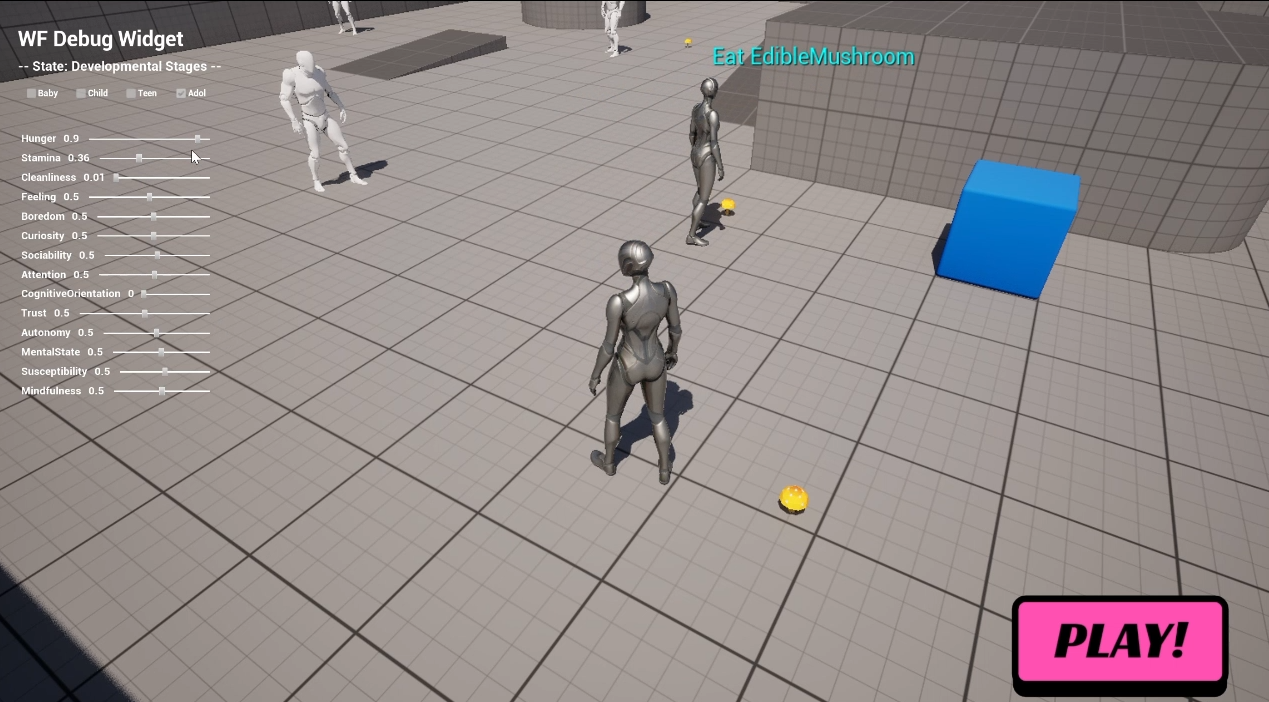
In the demo, the Utility behavior was set to Needs, which contained actions such as Satisfy Hunger, Restore Stamina, Get Clean, and Resolve Boredom. Each action had associated considerations, and these were prioritized in the order: Stamina → Hunger → Cleanliness → Boredom. Because of this setup, the AI executed actions in the sequence Restore Stamina, then Satisfy Hunger, then Get Clean, and finally Resolve Boredom.
With this setup, the AI performed not only simple actions like Go to Bed and Sleep, but also more complex ones like Cook or Paint. Adding new behaviors is now a straightforward process, requiring only a GOAP Action Set asset linking preconditions to effects. Below diagram shows chains of atomic actions to construct sequential and complex actions.
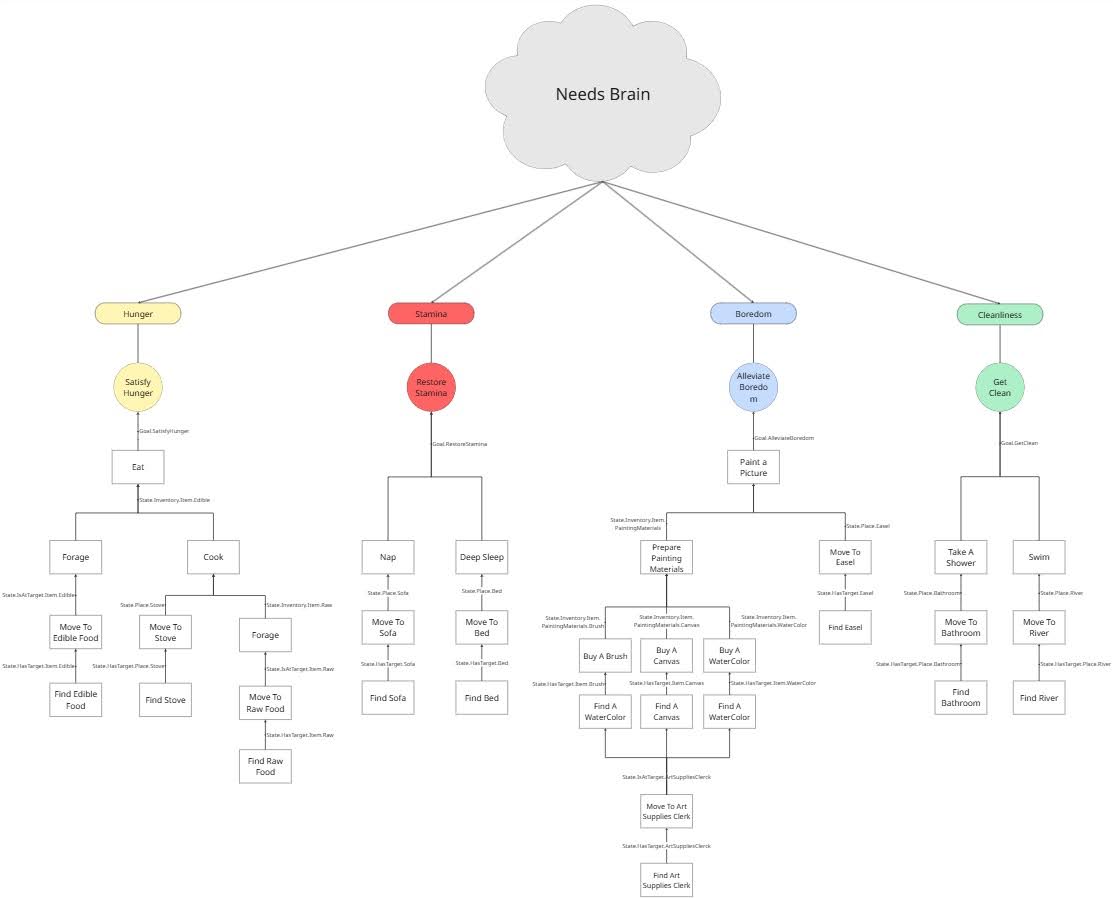
Environment Awareness
Dividing behaviors and integrating GOAP supported scalability and long-term planning. Still, one question remains: how does the AI know which *behavior* to activate in a given state?
1. Switching Behaviors with a Meta Brain
One approach was to use a meta brain that selects which behavior set to activate. This could be controlled by a game manager, an LLM, or another AI model. For example, if the AI is hungry and near a kitchen, the meta brain selects the Cooking behavior set, as shown in a below diagram.
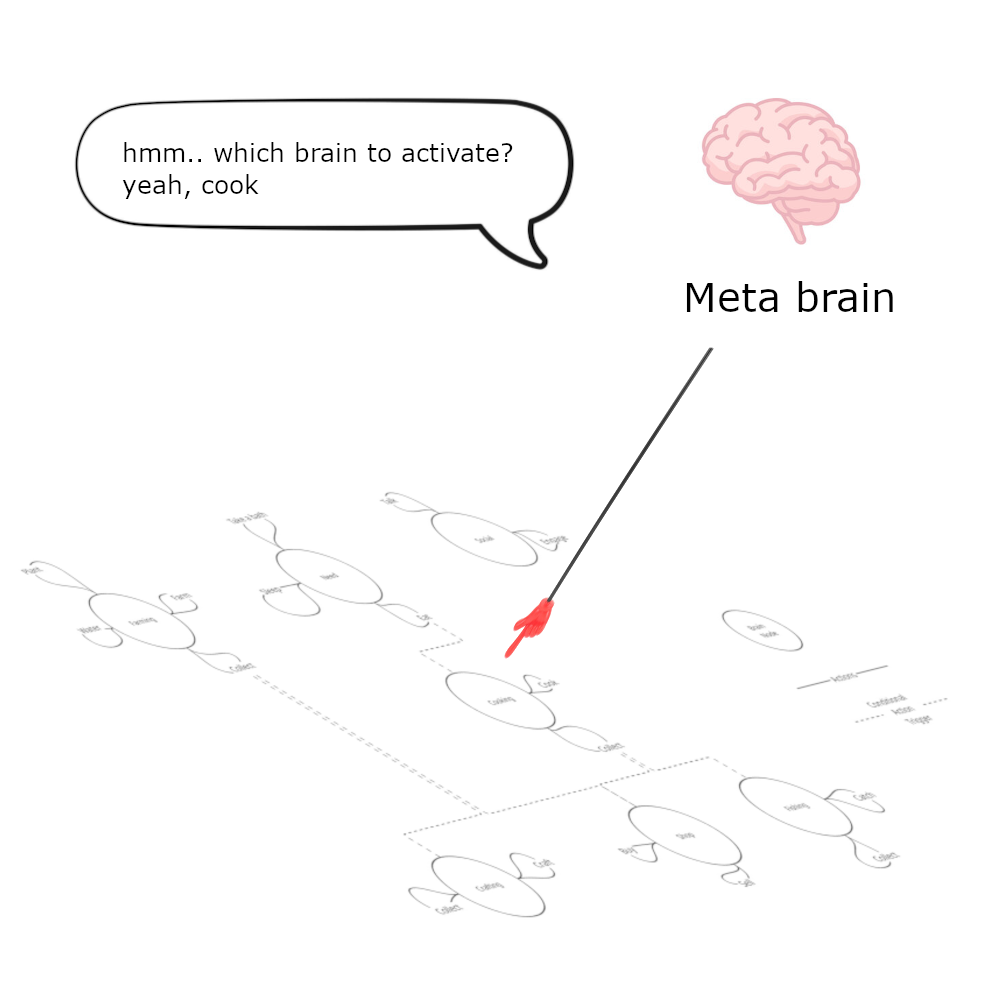
This setup is more top-down and deterministic: a preconfigured set of behavior themes (e.g., Cooking, Farming, Fishing) is available, and the meta-brain selects one—for example, Cooking if the AI is hungry or near the kitchen.
However, we identified a limitation. Choosing one themed behavior set can constrain natural, emergent behavior since the AI's actions are locked into that theme. Humans often diverge from context (e.g., farming but suddenly painting), but this setup makes such divergence unlikely.
While the meta-brain could switch behaviors, making these transitions feel natural and validating them remains a challenge.
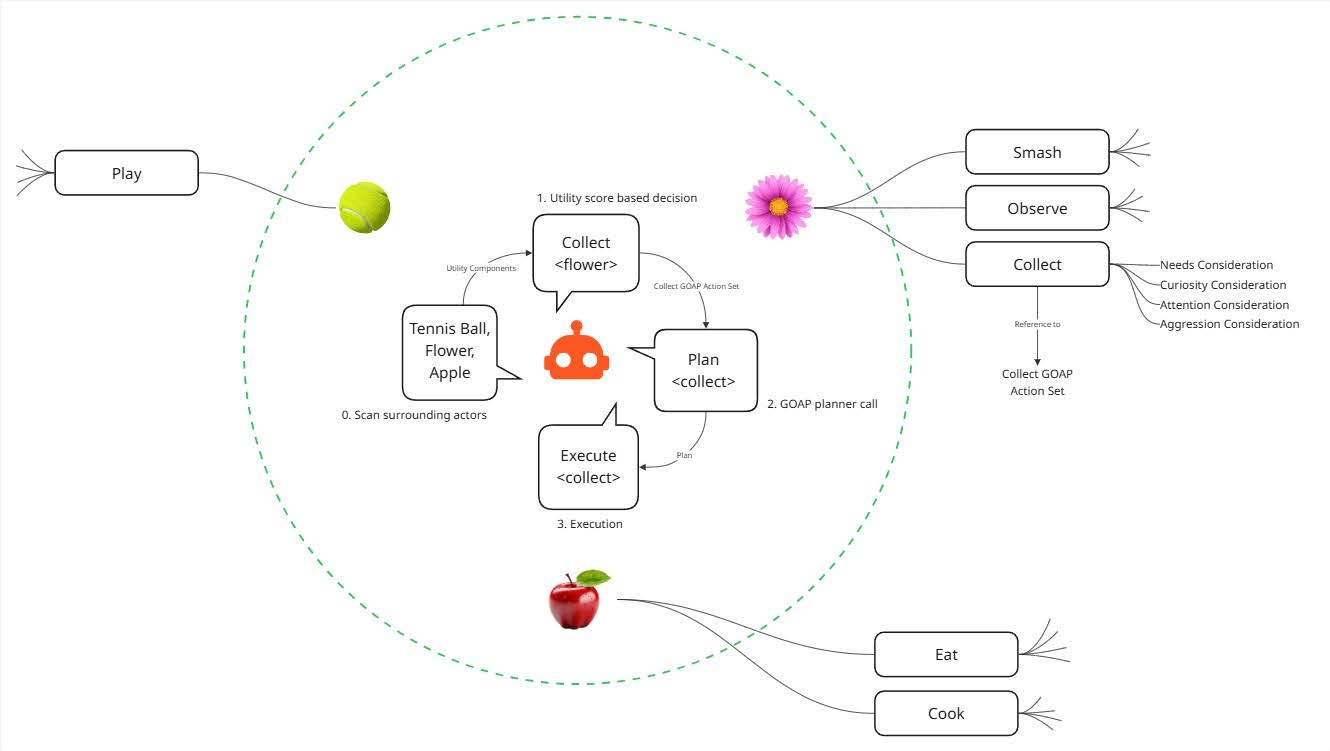
2. Dynamically Constructing Behavior Sets by Scanning the Environment
This led us to our most updated approach: dynamically constructing the behavior set based on the environment. This mirrors how humans and animals act. Our options depend on what's around us. For instance, we can sit because there's a chair nearby, or call a friend because we have a phone in our pocket.
The system works in four steps:
- Perception: The AI scans its surroundings. Each actor (object) in the environment has actions that are attached to it. The system collects those actions and forms the behavior set.
- Utility Calculation and Decision: Once actions are gathered, the AI calculates their utility based on considerations. For example, Get Clean may depend on Hunger, Stamina, and Feeling. After calculating, the AI selects one action with the highest utility.
- Planning: Utility AI does not execute the action directly. Instead, it sets the goal for the planner. GOAP then backtracks the required sequence of atomic actions to achieve that goal.
- Execution: The AI controller executes each planned atomic action step by step.
Preference and Long-Term Action Incentive
Dynamic behavior construction makes the AI environment-aware, but decision-making also requires subtle influences: preferences and long-term benefits. These factors shape human behavior and are critical for engaging AI.
Our current method incorporates them as bias terms into the utility score. The final utility probability is calculated by combining:
- Utility score: From considerations like stamina, hunger, cleanliness, boredom
- Preference: Cosine similarity between the AI's personality vector and candidate actions
- Long-term incentives: Bias toward actions with future benefits
This integration allows the AI's behavior to remain both context-sensitive and shaped by its unique personality and longer-term goals.
Detailed Implementation
Architecture
The Need for a Hybrid System
Utility AI excels at producing instantaneous and emergent behaviors. As the name suggests, Utility AI picks an action by calculating the utility of all possible actions it can perform, choosing an action with the highest utility score. To calculate the score, each action has associated considerations. Considerations can be weighted by curves (linear, exponential, inverse, … ) outputting values [0, 1]. Finally, simply multiplying all consideration outputs gives us a total utility score of one action, these scores are then compared to one another.
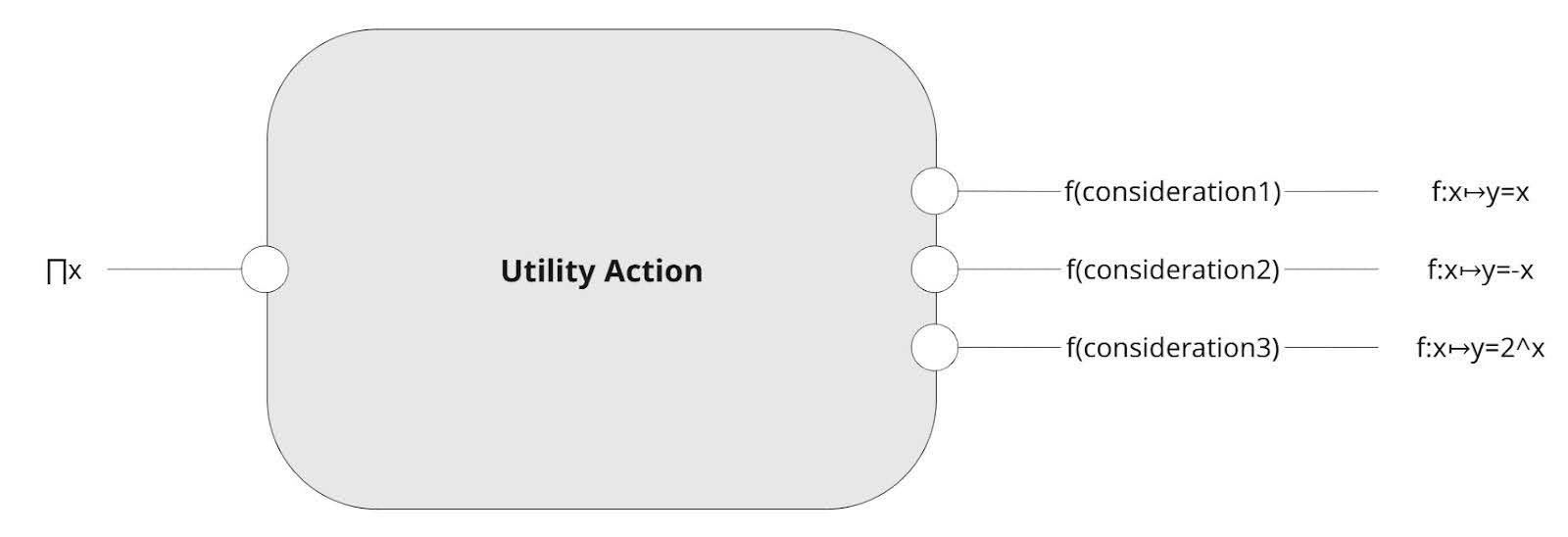
However, its biggest drawback arises when controlling a large number of actions. The system can become unstable, with multiple behaviors continuously competing against each other. Additionally, Utility AI is not ideal for long-term, planned sequences of actions. To resolve this problem, we propose GOAP as a low-level action execution layer.
The advantage of GOAP is its scalability. Even for highly complex behaviors, it is defined by primary atomic actions, consisting of pre-conditions and effects, allowing us to chain one action to another. These action components are reusable and can be combined to construct a wide range of behaviors.

Hybrid system of Utility AI and Goal Oriented Action Planning (GOAP)
The above diagram shows how the hybrid system works at an engine level.
1. Perception
- Inputs: World Actors scanned by AI.
- Process: For each Actor, AI extracts the available WiseFelineAction and their associated WiseFelineConsiderations.
- Output: These actions and considerations are dynamically added to the WiseFelineBehavior component which is attached to the AI blueprint.
2. Utility Calculation and Decision
Input: WiseFelineBehavior component dynamically added actions and considerations.
Process:
- Base Score: Calculated from the action's WiseFelineConsiderations.
- Bias 1 (Personality):
- Calculates the Cosine Similarity between the Actor's Preference Vector tag and the AI's Personality Vector.
- Bias 2 (Long-term Behavior Incentive):
- The Long-Term Action Incentive is used as a second bias.
- Final Score: The base score and both biases are combined using a SoftMax to produce the final [0, 1] utility probability.
- Goal: To combine the bias with the consideration score in a way that the final score does not saturate, while still meaningfully reflecting bias terms.
- Final Utility Score = Action Consideration Score + a * Preference Similarity (action) + b * Long-term action incentive
- Utility Probability = exp(FinalScore(action)) / Σ exp(FinalScore(all actions))
Output:
- The single WiseFelineAction with the highest utility score is selected.
3. Planning
Process:
- The selected WiseFelineAction contains a reference to an associated GOAP Action Set.
- The GOAP Component passes this referenced GOAP Action Set to the GOAP Planner.
- The GOAP Planner uses the atomic GOAP Actions to construct a sequence of steps that will achieve the goal.
Output: A viable plan.
4. Execution
- Input: A completed plan, which is a queue of atomic actions.
- Process: The AI agent follows the sequence of atomic actions in the plan until the goal is reached or the plan is interrupted.
- End: The cycle completes, and the AI is ready to start a new decision tick.
Potential Integration with AI Models
The hybrid framework presented here was intentionally designed not as a self-contained solution, but as a robust and modular interface for more advanced AI models. Its true potential is realized when its components are driven by the contextual reasoning and scenario interpretation capabilities of LLM.
Narrative Filter for Actions
While we moved from a deterministic "meta brain" to a more flexible, dynamic system that perceives actions from the environment, the role of a high-level director is still valuable, especially when it comes to more implicit action generation. Currently, AI is scanning world actors and calculating their utility, but in this calculation narrative-based nuance is excluded. The LLM can act as a filter on the AI's perception, interpreting environmental cues through narrative context rather than purely mathematical utility calculation.
Additionally, the LLM can help overcome a limitation of the current system, which filters possible actions primarily based on nearby objects. While human behavior is often constrained by immediate surroundings, context sometimes drives us to move elsewhere to perform an action. By providing broader context, the LLM gives the otherwise reactive system a sense of longer-term narrative coherence.
Outsourcing Personality and Attention Formation and Development
The Personality Vector and Long-Term Action Incentive are designed to be primary channels for an LLM to shape AI's characteristics.
- An LLM can be fed a qualitative backstory for a character. The LLM's task is to distill this narrative into a quantitative personality vector that our system can directly use in its utility calculations. The LLM extracts core personality traits, assigns weights based on story prominence, and continuously updates the vector as characters undergo experiences.
- A character's long-term dedication and attention items based on long-term perspective should evolve based on their experiences and relationships. The LLM manages this by dynamically adjusting incentives and attention priorities in response to narrative developments. Major narrative events trigger comprehensive longer perspective attention reassessment.
Serving as a Memory Module
Programming AI memory is often labor-intensive. An LLM can serve as a flexible, context-aware memory module. This is highly effective for social interactions, where past experiences heavily influence future behavior.
Instead of manually scripting reactions, the system can log interactions as text. When encountering a character, the AI queries the LLM with the memory log. The LLM’s response can create a temporary social bias, altering the utility of social actions based on past experiences.
Injecting Randomness and Surprise
Modularity is a core design principle of this framework. This allows key components to be swapped with LLM-based alternatives. The Utility AI goal selector and the GOAP planner are two such components.
These systems currently use fixed logic, which can lead to predictable behavior. Replacing them with an LLM can inject variability. For example, the GOAP planner generates a predictable sequence of actions to achieve a goal. An LLM-based planner could generate an unexpected sequence of actions. This change introduces randomness into the system, creating surprising and more believable AI behavior for players.
Conclusion and Next Steps
This post introduced a hybrid AI framework that combines Utility AI with Goal-Oriented Action Planning (GOAP). The system uses environmental perception to dynamically construct its available actions, creating behavior that is both context-aware and scalable. By integrating a GOAP planner, the framework supports complex, long-term actions, overcoming the limitations of using Utility AI alone. The result is a modular system that serves as a practical interface between high-level AI models and the concrete actions of in-game characters.
Future work will focus on two key areas:
- Social Behaviors in a Multi-AI Setting: The immediate goal is to expand the framework to support complex social interactions among multiple AI agents. This requires enhancing the perception system to not only interactable objects but also the states, personalities, and intentions of other AIs.
- Integration with Advanced AI Models: The final step is to fully integrate this framework with an LLM. As discussed, an LLM can drive character personality, memory, and filter actions based on narratives. The next phase will involve implementing these connections, allowing an LLM to influence the AI's decisions and create more surprising individual characters.