Using Unity to Help Solve Reinforcement Learning
Dec 2024
Authors:
- Connor Brennan
- Andrew Robert Williams
- Omar G. Younis
- Vedant Vyas
- Daria Yasafova
- Irina Rish
Abstract
Introduction
Reinforcement learning and meta-reinforcement learning research faces significant challenges in creating diverse, complex environments that can test the adaptability and generalization capabilities of learning agents. The United Unity Universe (U3) toolkit addresses this need by providing a comprehensive framework for building innovative reinforcement learning environments using the Unity engine, combining the flexibility of XLand with rapid prototyping capabilities.
Toolkit Overview
The United Unity Universe provides researchers with a complete ecosystem for developing and testing reinforcement learning algorithms in diverse 3D environments.
OpenXLand Implementation
A robust implementation of OpenXLand, a framework for meta-RL based on XLand 2.0, providing the foundation for creating complex, procedurally generated environments.
User-Friendly Interface
An intuitive interface that allows users to easily modify procedurally generated terrains and task rules, enabling rapid experimentation and iteration.
Curated Environment Collection
A carefully selected collection of terrains and rule sets that serve as starting points for research and provide benchmarks for comparing different approaches.
Key Features
The U3 toolkit provides several key features that make it an essential tool for reinforcement learning research and development.
High-Level Language
A domain-specific language for defining tasks, rewards, and environment rules that abstracts away low-level implementation details.
Procedural Generation
Advanced procedural generation capabilities for creating diverse, challenging environments with varying terrain, obstacles, and task configurations.
Multi-Agent Support
Built-in support for multi-agent scenarios, allowing researchers to explore cooperation, competition, and emergent social behaviors.
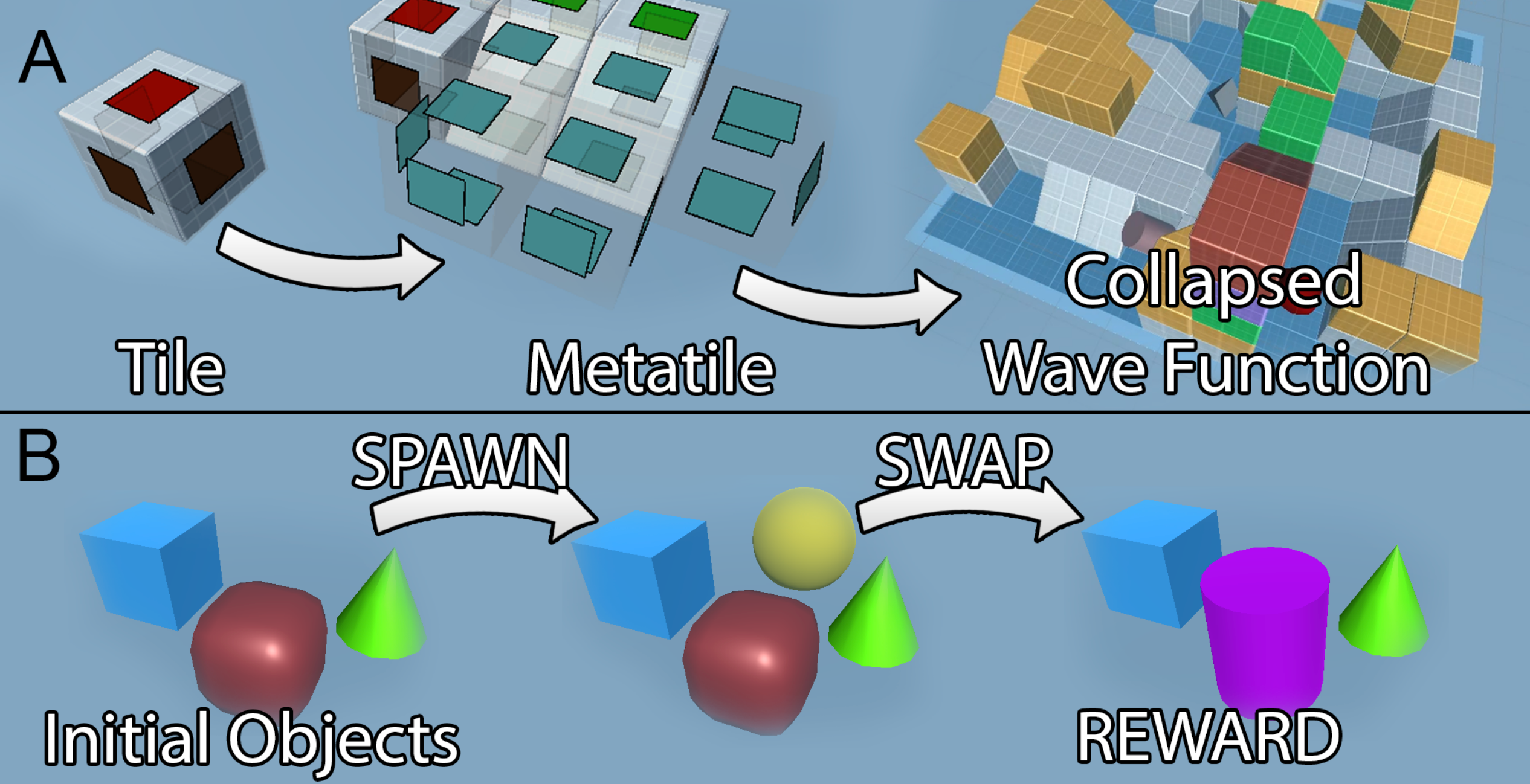
Technical Implementation
The U3 toolkit is built on a robust technical foundation that ensures flexibility, performance, and ease of use.
Unity Integration
Seamless integration with the Unity game engine provides access to powerful rendering, physics, and animation capabilities, as well as a large ecosystem of assets and tools.
Python API
A comprehensive Python API allows researchers to interact with environments programmatically, supporting popular reinforcement learning frameworks like PyTorch, TensorFlow, and JAX.
Distributed Training
Built-in support for distributed training enables efficient scaling across multiple machines, accelerating experimentation and research.
Benchmark Environments
The U3 toolkit includes a set of benchmark environments designed to test specific aspects of reinforcement learning algorithms.
- Navigation: Testing path planning and spatial reasoning
- Manipulation: Evaluating fine-grained control and object interaction
- Cooperation: Assessing multi-agent coordination and communication
- Adaptation: Measuring agent ability to adapt to changing rules and environments
- Generalization: Testing transfer learning across related but distinct tasks
Baseline Implementations
To facilitate research and comparison, the toolkit includes implementations of several state-of-the-art reinforcement learning algorithms.
- Proximal Policy Optimization (PPO)
- Soft Actor-Critic (SAC)
- Deep Q-Network (DQN) variants
- Meta-learning algorithms (MAML, RL²)
- Multi-agent algorithms (MAPPO, MADDPG)
Case Studies
The paper presents several case studies demonstrating the capabilities of the U3 toolkit in different research scenarios.
Meta-Learning for Adaptation
A study showing how agents can be trained to quickly adapt to new tasks and environments, demonstrating the toolkit's value for meta-reinforcement learning research.
Emergent Social Behaviors
An exploration of how complex social behaviors emerge in multi-agent scenarios, facilitated by the toolkit's flexible environment creation capabilities.
Curriculum Learning
A demonstration of how the procedural generation features can be used to create increasingly challenging environments for curriculum learning approaches.
Community and Ecosystem
The U3 toolkit is designed to foster a vibrant research community and ecosystem around reinforcement learning in Unity.
- Open-source codebase with MIT license
- Comprehensive documentation and tutorials
- Environment sharing platform for community contributions
- Regular challenges and competitions
- Integration with popular reinforcement learning benchmarks
Conclusion
The United Unity Universe toolkit represents a significant advance in reinforcement learning research infrastructure, combining the flexibility and power of the Unity engine with the innovative meta-RL framework of XLand. By providing a comprehensive, user-friendly platform for creating diverse, challenging environments, U3 enables researchers to focus on developing and testing novel algorithms rather than building infrastructure. We believe this toolkit will accelerate progress in reinforcement learning, particularly in areas requiring complex, procedurally generated environments and multi-agent scenarios.
For more details, see the original paper: Using Unity to Help Solve Reinforcement Learning